数据库高可用方案简述
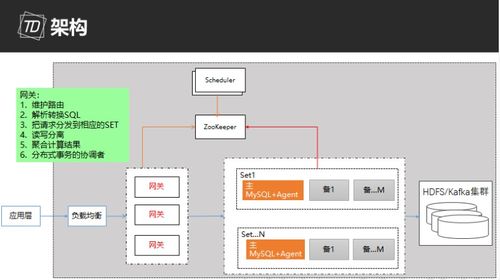
数据库作为现代应用的核心,其高可用性是保障业务连续性的关键。常见的数据库高可用方案旨在通过冗余、故障检测与自动切换等机制,最小化服务中断时间,确保数据安全与访问不中断。
1. 主从复制(Master-Slave Replication)
这是最基础的高可用方案之一。主节点(Master)处理所有写操作,并将数据变更异步或同步复制到一个或多个从节点(Slave)。从节点通常用于处理读请求,分担主节点负载。当主节点故障时,可手动或通过工具将某个从节点提升为新主节点。其优点是实现简单、成本较低,但故障切换通常非完全自动,且同步复制可能影响性能。
2. 主主复制(Master-Master Replication)
两个或多个节点均可处理读写请求,并相互复制数据变更。这提供了更高的可用性和负载均衡能力。它需要处理数据冲突(如同时写入相同记录),对应用程序和数据库设计有更高要求。通常适用于写操作较少或可分区场景。
3. 数据库集群(Database Clustering)
集群方案通过共享存储或多节点数据同步,实现更高程度的自动故障转移。例如:
- 共享磁盘集群:多个数据库节点共享同一存储(如SAN),当活动节点故障时,备用节点可迅速挂载存储并接管服务。常见于Oracle RAC等商业数据库。
- 无共享集群:每个节点拥有独立存储,通过分布式协议(如Paxos、Raft)保持数据一致性。例如,MySQL Group Replication、Percona XtraDB Cluster和许多NewSQL数据库(如TiDB、CockroachDB)。这类方案通常支持自动选主与故障恢复。
4. 基于中间件或代理的高可用
使用中间件层(如ProxySQL、MaxScale)或连接代理来管理数据库连接。中间件可以监控后端数据库节点的健康状态,并在主节点故障时,自动将流量路由到健康的备用节点。这常与主从复制结合,对应用透明,但引入了额外的网络跳点和单点故障风险(需对中间件本身做高可用)。
5. 云数据库托管服务的高可用方案
主流云服务商(如AWS RDS、Azure SQL Database、阿里云RDS)提供了内置的高可用选项。通常基于上述技术(如主从复制、集群),但由云平台自动化管理故障检测、切换、备份与扩展。用户只需选择高可用版本,即可获得通常承诺99.95%以上的可用性SLA,大大降低了运维复杂度。
6. 逻辑与物理备份结合
虽然备份本身不是实时高可用方案,但它是灾难恢复的基础。定期全量备份与增量备份,结合时间点恢复(PITR),可在数据误删或严重故障时恢复服务。对于高可用要求极高的场景,备份应跨地域或跨云存储。
选择高可用方案时,需权衡成本、性能、数据一致性要求(如强一致性vs最终一致性)、运维复杂度及恢复时间目标(RTO)与恢复点目标(RPO)。通常,从主从复制起步,随着业务增长,可逐步演进到集群或云托管方案,以确保数据库服务持续稳定运行。
如若转载,请注明出处:http://www.1dingyouchebeta.com/product/75.html
更新时间:2026-06-19 00:59:37